Friday, April 4, 2014
Pretty nice blog post on sorting and efficiency. Check it out!
CSC148 SLOG at UofT: Assignment Topic Three: Sorting and Efficiency (La...: The run-times of algorithms in computer science are categorized using different function types (logarithmic, exponential, polynomial...
Thursday, April 3, 2014
Week 12: constant-time access and review
Final Post for CSC148H1
It is with a small bit of both sadness and relief that I shall write this final SLOG post for CSC148. I have had a wonderful time in this course, and will look forward with eagerness to moving onto CSC207 this fall. Hopefully, I will see many fellow friends and classmates next semester.
This week's final lecture covered the concept of constant-time access, and reviewed some material covered in past lectures in preparation for the final exam.
Constant-time access refers to the practice of storing references to elements in consecutive memory addresses such that if the index of a list is known, the element contained at that index could be accessed within constant time. The downside to Python list's constant-access feature is most evident when we start dealing with huge lists that requires descriptive names in order to have a meaningful way to access values associated with those specific memory addresses.
Be aware...
It is worth noting that when we convert strings, or tuples into integers using hash, we have to be mindful of the potential for collision to occur (i.e. two of the same key refers to two different elements). It should also be noted that the number of bits that could be stored in memory is dependent on the size of the memory itself. Thus, it is not possible to store exponentially large number of bits in memory, which becomes a problem when we deal with very large lists that requires a large number of keys.
Studying for finals
Given that the final exercise for CSC148 is due tomorrow, it seems like at this point, all thats left in terms of course work is to finish up our SLOGS and prepare for finals. I managed to score a pretty good grade on the last term test, but I was quite honestly really surprised to find that the class average for our section was 45%. Hopefully during the CSC148 finals, we won't be dealing with such low averages. This leads to a sort of side question: how are other students in our section studying for the finals? Figured I'd leave this open question on the blog (though I HIGHLY doubt if anyone will be answering it here, I'd really appreciate it if you leave a comment below), and will probably post once more on Piazza. It seems like throughout this entire semester, most CSC148 students interacted with one another via Piazza rather then throughout the slogs. Amazingly, there is not a single comment on any of my posts, despite repeated requests for them. Seems like a lot of people are just not really into the whole idea of a SLOG. Just food for thought.
And finally...
Congratulations to all fellow CSC148 students for surviving the course! I'll be looking forward to seeing you all again next year! Good luck on the finals!
And to end with some humour...

Cheers,
Fellow CSC148 Winter 2014 Student
Image cite:
Final Exams! - News - Bubblews. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://www.bubblews.com/assets/images/news/1831247139_1362455100.png>
Wednesday, April 2, 2014
Searching and Sorting Efficiency

Search and sorting:
Searching and sorting are common functionalities often employed in programming. Whether it be looking for the largest integer value in a list, searching for a specific name in a dictionary, or sorting a list in alphabetical order, searching and sorting algorithms are used to find (or sort) the things that we are looking for.

Which searching (and sorting algorithm) should I use?
However, there exists a plethora of differing sorting algorithms, ranging from Bubble Sort, Quick Sort, Merge Sort, and etc., which then leads to another whole host of searching algorithms that work on unsorted lists, sorted lists, and almost-sorted lists. Given this wide ranging availability of different options of searching and sorting a given set of data, how do programmers approach the problem of determining precisely which sorting and searching algorithm to use? The answer: it depends on the context of the problem. However, a simple analysis using the big-Oh notation of a function can tells us important information to determine which searching or sorting algorithm to use within a given problem.

Binary search in action
Example of merge sort
What is big-Oh notation?
Big-Oh notation is commonly used in programming to determine the searching or sorting efficiency of a given algorithm. To be more precise, the big-Oh notation of a function gives us its upper bound on its runtime as the size of its input increases. Sorting algorithms such as bubble sort have a runtime of O(n^2). Merge sort, another sorting algorithm, have a runtime of O(n log n), but uses more memory. Binary search (see image above), which employs a divide and conquer strategy, has a runtime of O(log n). A pure binary search however, will only work on a sorted list. Below is a table that displays the runtime efficiency of various searching and sorting algorithms in big-Oh notation.
On a final note...
When using big-Oh notation, it is important to use meaningful notation in describing the asymptotic runtime behaviour of a function. For example, it is perfectly legitimate to say that merge sort has a runtime of O(n^2). However, this doesn't give us an accurate approximation of the runtime behaviour of merge sort since O(n log n) provides a much tighter bound than O(n^2).
Image Citation:
What Should I Do If My System Isn't Working Properly? Digital image. N.p., n.d. Web. <http://www.sdasecurity.com/wp-content/uploads/2013/04/security-system-error-advice.jpg>.
Electric Engineering and Computer Science. Digital image. N.p., n.d. Web. <http://engineering.vanderbilt.edu/images/dept-slide-show/eecs-slide-4.jpg>.
Binary Search. Digital image. N.p., n.d. Web. <http://en.algoritmy.net/image/id/40163>.
Friday, March 28, 2014
Week 11: sorting, recursion limits
Busy, busy, little bees
This week has been a painfully busy week for me; got a few assignments due by the end of this week and a couple final exams that I need to study for, so I'm going to try to keep this blog post short.
This week's lecture basically went over different sorting methods, and expanded a little further on the concepts we've talked about last class. We went over some more big-Oh notation stuff, then went on to talk about recursion limits. One of the things we looked at during lecture was the idea of using 'memoization' to improve the efficiency of a function. We specifically looked at the python implementation of the Fibonacci function, then improved its runtime through the use of memorization (the difference in speed was significant).
Tim-Sort
Another topic we covered in class that I thought was interesting was the Tim-Sort. To my understanding, tim-sort is the standard sorting algorithm used in the Python standard library. It utilizes the fact that in most real-world data, lists tend to be already partially sorted. I do wish that the instructor had been a little bit more clear on exactly how tim-sort works; we only briefly went over tim-sort during lecture. I understand that its probably outside the domain of this course, but I think it would have been pretty cool to get a more in-depth rundown on tim-sort out of intellectual curiosity. My understanding on tim-sort is relatively limited, so I would really appreciate it if someone reading this post might be willing to enlighten me on how tim-sort works.
Until next time!
Tim-Sort
Another topic we covered in class that I thought was interesting was the Tim-Sort. To my understanding, tim-sort is the standard sorting algorithm used in the Python standard library. It utilizes the fact that in most real-world data, lists tend to be already partially sorted. I do wish that the instructor had been a little bit more clear on exactly how tim-sort works; we only briefly went over tim-sort during lecture. I understand that its probably outside the domain of this course, but I think it would have been pretty cool to get a more in-depth rundown on tim-sort out of intellectual curiosity. My understanding on tim-sort is relatively limited, so I would really appreciate it if someone reading this post might be willing to enlighten me on how tim-sort works.
Until next time!
Thursday, March 20, 2014
Week 10: sorting big-oh
To talk briefly about A2...
Assignment #2 was due during this week, so that had taken up a significant amount of my free time. I thought the assignment was a relatively straight forward project that wasn't extremely difficult, and I'm pretty sure most people thought it was an relatively easy assignment. Looking forward to get my marks back for this project. Guess all that's left at this point is just preparing for T2 test and the finals. How did everyone else feel about A2? Did you think it was a hard/easy project? Leave your thoughts on the comment section below (please)!
Moving on to this week in lecture...
In this week's lecture, we talked about the big-Oh notation of some popular sorting algorithms, specifically with references to quick sort and merge sort. Among the sorting algorithms that we have gone through in the past week, quick sort and merge sort are the only ones that have O(n log n) in average case, versus the poor performance of sorting methods such as bubble sort and selection sort which have O(n^2).
Sun Tzu said: Divide and Conquer!
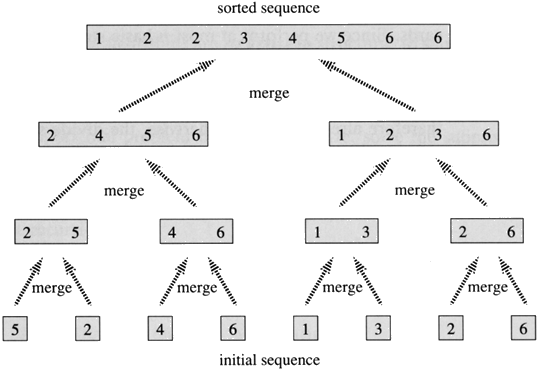
Quick sort and merge sort are interesting because both utilize a divide and conquer strategy to achieve optimum efficiency. For those who have never heard of the term divide and conquer, in the case of programming, divide and conquer strategies break a problem down in smaller problems, such that the problem as a whole becomes easier to solve. For example, merge sort works by repeated dividing a list into small sub-lists until every sublist is of length 2 or smaller, at which point each sublist is then sorted and repeated merged together, until a sorted list is created (see image below).
Final thoughts for the day...
As usual, what are everyone else's thoughts on the different sorting algorithms seen in lecture and lab? Which one do you think is the best? Do YOU know of an even quicker way to sort a list? Please let me know in the comments section below!
In the meanwhile,
Cheers
Image Cite:
Merge Sort. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/Gifs/mergeSort.gif>.
In this week's lecture, we talked about the big-Oh notation of some popular sorting algorithms, specifically with references to quick sort and merge sort. Among the sorting algorithms that we have gone through in the past week, quick sort and merge sort are the only ones that have O(n log n) in average case, versus the poor performance of sorting methods such as bubble sort and selection sort which have O(n^2).
Sun Tzu said: Divide and Conquer!
Quick sort and merge sort are interesting because both utilize a divide and conquer strategy to achieve optimum efficiency. For those who have never heard of the term divide and conquer, in the case of programming, divide and conquer strategies break a problem down in smaller problems, such that the problem as a whole becomes easier to solve. For example, merge sort works by repeated dividing a list into small sub-lists until every sublist is of length 2 or smaller, at which point each sublist is then sorted and repeated merged together, until a sorted list is created (see image below).
Merge sort in action
Final thoughts for the day...
As usual, what are everyone else's thoughts on the different sorting algorithms seen in lecture and lab? Which one do you think is the best? Do YOU know of an even quicker way to sort a list? Please let me know in the comments section below!
In the meanwhile,
Cheers
Image Cite:
Merge Sort. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/Gifs/mergeSort.gif>.
Wednesday, March 12, 2014
Week 9: BSTs and big-Oh
In this week's lecture, we went over the topic of binary search trees and the use of big-Oh notation in describing runtime behaviour of functions. The topic of binary search trees was relatively straight forward, and simply expanded some more on the concept of linked data structures that was done last week. The topic of big-Oh, however, was much more interesting, since big-Oh could could as a useful measure of algorithmic runtime efficiency.
Binary Search Trees
The explanation of how a binary tree works in lecture shared many similar similarities with the LLNode class done last week. Like the implementation of LList, the implementation of BST utilized both BTNode and a wrapper class. We then went over some simple tree traversal methods that was covered in an earlier lecture when binary trees were first introduced. I thought the section on deletion of a node in a BST was quite interesting, since it had never come across to me that the deletion of a node could be problematic, given that some nodes may contain two children. The basic concept of node deletion was relatively straightforward (see image below), but I do plan on reviewing the material some more to make sure I get the material into my head.


Big-Oh Notation
The concept of big-Oh notation was in fact something that I was already quite familiar with, since we had covered the concept in CSC165 during a previous week. I actually wished we had talked about big-Oh a little bit more, since the instructor had only made brief mentions of it as the lecture progressed. Obviously, the concept of big-Oh itself was relatively simple: it provides an upper bound on the runtime as the input size gets increasingly large. Hopefully we could cover the concept at a more in depth level during next lecture.
To other CSC148H1 Students:
What do you guys think of the topics we've covered this week? I'm sort of curious about how others feel about big-Oh notation and binary search trees. I can imagine that some of this materials may be a little bit hard to digest, so it would interesting to see how others are faring with it all. Leave your comments below!
Image citation:
4.4 Binary Search Tree. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://lcm.csa.iisc.ernet.in/dsa/img168.gif>.
Big-Oh Design. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://i0.wp.com/www.stampede-design.com/blog/wp-content/uploads/2013/08/big-o11.png?resize=498%2C512>.
Binary Search Trees
The explanation of how a binary tree works in lecture shared many similar similarities with the LLNode class done last week. Like the implementation of LList, the implementation of BST utilized both BTNode and a wrapper class. We then went over some simple tree traversal methods that was covered in an earlier lecture when binary trees were first introduced. I thought the section on deletion of a node in a BST was quite interesting, since it had never come across to me that the deletion of a node could be problematic, given that some nodes may contain two children. The basic concept of node deletion was relatively straightforward (see image below), but I do plan on reviewing the material some more to make sure I get the material into my head.
Binary search tree node deletion
Big-Oh Notation
The concept of big-Oh notation was in fact something that I was already quite familiar with, since we had covered the concept in CSC165 during a previous week. I actually wished we had talked about big-Oh a little bit more, since the instructor had only made brief mentions of it as the lecture progressed. Obviously, the concept of big-Oh itself was relatively simple: it provides an upper bound on the runtime as the input size gets increasingly large. Hopefully we could cover the concept at a more in depth level during next lecture.
To other CSC148H1 Students:
What do you guys think of the topics we've covered this week? I'm sort of curious about how others feel about big-Oh notation and binary search trees. I can imagine that some of this materials may be a little bit hard to digest, so it would interesting to see how others are faring with it all. Leave your comments below!
Image citation:
4.4 Binary Search Tree. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://lcm.csa.iisc.ernet.in/dsa/img168.gif>.
Big-Oh Design. Digital image. N.p., n.d. Web. 4 Apr. 2014. <http://i0.wp.com/www.stampede-design.com/blog/wp-content/uploads/2013/08/big-o11.png?resize=498%2C512>.
Saturday, March 8, 2014
Week 8: linked structures
Brief Overview:
This week's lecture dived into the topic of linked data structures in programming. We first looked at the concept of a linked data structure represented as a linked list by analyzing the LLNode class and its associated wrapper class as provided in lecture. A handy diagram from the CS department at SFU provided below gives a visual representation of what a linked list looks like in the abstract.

We then moved on to the idea of a binary search tree, which was essentially a linked list, but with two children (see diagram provided below). The code implementation for both types of data structure was relatively simple. In the code provided during lecture, the implementation of a linked list and a binary search tree both used a wrapper class as a method of organization (BTNode and BST; LListNode and LinkedList).

"Flattened" binary tree?
I had noticed that a LLNode object was essentially a BTNode object, except for the small difference where LLNode has a single child whereas BTNode has two. In fact, had the instructors not explicitly stated the differences between the two through the use of descriptive names, it would have been very difficult to distinguish the differences between the two. This little observation made me realize the importance of having meaningful names when creating classes to represent linked data structures, since confusion can easily arise when we start naming attributes or methods in the LLNode class with names that are typically reserved for the BTNode class. At the same time, its interesting that from the perspective of the python interpreter (assuming that the interpreter was somehow sentient), how a LLNode or BTNode class functions is unrelated with respect to the names given to the various methods and attributes of that class; the names exist solely to infer meaning to the code for the person reading it. Its a simple observation, yet quite profound at the same time the more that I thought about it.
Final Thoughts
How is everybody else faring with the concept of linked structures? Do you think its difficult/easy? Confusing/clear? Leave your thoughts in the comment section below!
Image citation:
Recursive Definition of a Linked List:. Digital image. N.p., n.d. Web. 1 Apr. 2014. <http://www.cs.sfu.ca/~bbart/225-beta/ind5.png>.
Binary Search Tree. Digital image. N.p., n.d. Web. 1 Apr. 2014. <http://upload.wikimedia.org/wikipedia/commons/a/a9/Unbalanced_binary_tree.svg>.
Subscribe to:
Posts (Atom)